Until Microsoft implements change feed notifications for deletions we have to soft delete items in Cosmosdb if we use change feed notifications.
TL;DR
Cosmosdb has a handy feature where it journals changes which can then be read in another process. My use was for updating an Azure search index (Elastic search variant) whenever I made a change.
But… how do we handle deletions?
Hidden in the documentation is the information that ,,albeit all changes (within a shard) is guaranteed to be in chronological order it is always the last (present) item handed to the change feed process. So when an item is deleted there is no item and, due to implementation, also no event.
Remedy 1: Soft delete the item by marking it as “deleted”. This is a common approach in many a system. A drawback is that the repository will end up with stale data.
Remedy 2: Soft delete the item as above. Then make sure this information has been conveyed (in my case the item should be deleted from the search database) before properly deleting it. This is a more complex solution where the logic still has to handle soft deleted items while also adding the complexity of yet a process to scan(?) the repo for items to delete.
Your turn
I have found no uservoice, github or azurefeedback item for voting on getting a delete event; the closest is an item for getting a event for it in Azurefunctions. In lack of better place I voted there; so can you if you have the need.
Update
I wrote a suggestion of my own here at azurefeedback. I did try to find an existing suggestion but failed. Am I the only one deleting data? Or the guys at Microsoft will find an already existing suggestion where I can move my votes.
Comments about rules I have found but often not followed
“Do not postfix enums with Enum.” To be honest – I have often found it the best solution to postfix with Enum.
“Do not organise namespaces after company hierarchy.” Even though Conway’s law is a thing, a system should not keep the history of a changed organisation chart.
“Do not use List<T> on public methods.” List<T> is a complex beast. But using IEnumerable<T> might have some reiteration performance impact, that is when you have to loop through the same collection twice.
Other comments
“Carefully choose names for your types, methods, and parameters.” Naming things can be hard so take your time and discuss with your colleagues.
“Do not create mutable value types.” I totally agree. It is easier to debug imutable. Often when I track down a but I have only a (bad) call stack and the name of a public method and some source code. Then it is very important the code is easy to follow by hand.
“Do not throw
1
Exception
or
1
SystemException
.” I can count on the fingers on one hand the people, beside me, that bother with writing a proper exception. Visual studio makes it easy, just write ‘exception’ and then tab and you get the full template.
“Members returning arrays should return copies of an internal master array.” I is good OOP practice to not publish internal stuff. Correction, it is cruical OOP practice to not expose the innards of a class.
Other other comments
“Prefer classes over interfaces.” Why? Context please.
IMO the linked article forgot to mention that public methods should not have optional parameters as they are compiled into the caller and not callee.
Avoid public as any change to them might break the API. Unfortunately Visual studio defaults new classes (and methods?) to public so I see them everywhere.
I am currently experimenting with using a virtual machine for my development. I have earlier done it through OSX/Win by the means of Parallells but now I am trying a Win/Win solution with Hyper-V.
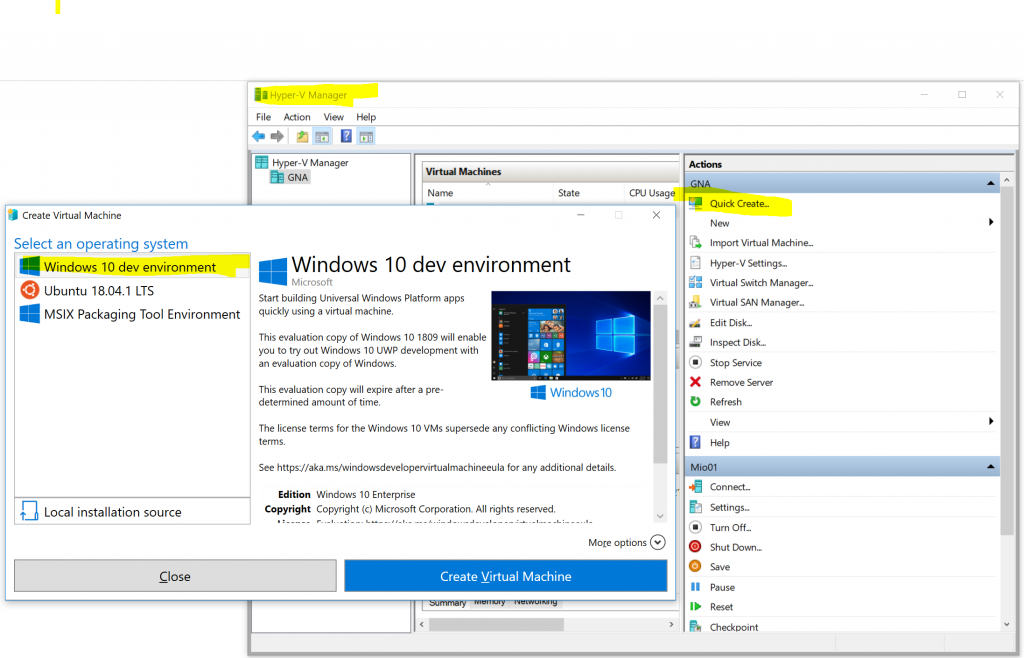
Every 30 days or third month, I have seen both, is for how long the license is valid, I do a Hyper-V Manager->Quick create->Windows 10 dev environment and 30 minutes later, or so, the new VM is up and running.
Microsoft packages and delivers the new download on the very day of expiry so it is not possible to download a VM a day before and prep it. It means the VM is out of date the moment you have installed the new one.
But there is a work around, open a console in admin and
1
slmgr –rearm
and you have 90(?) new days. This can only be done once per VM.
Also note that the Hyper-V manager gui, as depicted below, does not refresh its “Create virtual-machine”-content so the date of the template might be old. Restart (the host machine?) to refresh it.
The mandatory screen shot.
It comes with Visual studio, Visual studio code, Powershell 6 and some dotnet preinstalled. All I have to do is start VS and tell it to update itself..
I have checked that all chocolatey packages I reference are “trusted package”. I cannot know if they packages remain “trusted package” at the time you are reading this. The choice is yours.
To make it even cooler one can install more stuff, like oh-my-posh. For it to work one needs a new font “Cascadia Code”, and Windows terminal has to be updated to use it.
1
"fontFace": "Cascadia Code PL"
1
Import-Module oh-my-posh
1
Set-ThemeParadox
I like to have a clear separator by every promp. So I might add a newline before the prompt
I believe Keyboard1337 is a zip if you git clone BecarroInamovible. If so, you don’t have to download Keyboard1337.
Otherwise download
1
Keyboad 1337.zip
. Unblock. Unpack. Install. Run Keyboard 1337\l337\setup.exe (yupp. there’s a typo there) Language preferences -> Keep English(Sweden) and English(United States). The latter is Keyboard1337
If these 3 issues aren’t a problem in you case, be reluctant to use an O/RM as an O/RM brings a bunch of other problems.
Type security
When you get the Customer.Verified out of a database the code already knows it is a boolean. No explicit type casting or declaring is needed as it is done elswhere, once and for all.
Now this isn’t totally true but depends on whether LINQ or HQL (or for another O/RM) you are using. But basically it is true, because of solid Right-left copying
Right-left data copying
Copying data from a recordset to the Entity is done by the OR/M and configured once and for all. Unlike a programmer it won’t forget to copy a field in an obscure corner in your code base.
It isn’t hard to write a data copying function for this simple case and dragging a whole OR/M into the project is a lot of dependencies for little use.
Turn around
When the scheme is changing fast, like in the beginning of a project, or when prototyping, an O/RM is of great help to change in one place and let the coding tools and compiler do the rest of the changes in the project.
Schemes tend to solidify after a while and only change in small increments so speeding up the first 3 months for having a rucksack the coming 6 years might not be the best solution.
In production we usually rely on logs to track down an error.
Even worse; in production we have more data and more logging to sift through than in development. The trees can be lost in the woods. If we are more unlucky we also have a time restraint.
To learn how to read a log file we must train. This means reading log files. And to read the we must first write to them; in a readable way.
So I write log files and read them to find my errors already in development. Training for production.
Learn to write
Too little information is bad. This is the usual case. Too much information is bad too as we cannot see the flow of the program due to uninteresting information. Writing the exact amount of information for every time is probably not doable but by training I learn and get better at it.
Readable code
If we develop the application through setting breakpoints and inspecting variables we are in a bad spot when production error happens as we seldom can do that.
All we have is a log with a stack and possibly a rough idea of the input.
If I instead learn to read the code and trace the execution path manually, already in the development phase, I am in a much better position when production hits the proverbial fan.
Startup time
Connecting the debugger takes time. Just starting the program is faster.